One WEIRD Trick for Speeding Up ORDER BY That You Probably Shouldn't Use
I was digging into a performance issue at work recently and found THE WEIRDEST way of speeding up a query that uses ORDER BY. When testing against our replica database, I was getting results up to 100 times faster than before.

I originally posted this on dev.to, and I'm reposting it here because I often link people to it when they are trying to understand Postgres performance issues.
I was digging into a performance issue at work recently and found THE WEIRDEST way of speeding up a query that uses ORDER BY. When testing against our replica database, I was getting results up to 100 times faster than before.
"Too good to be true!" I thought. Well, it turns out that it is sort of too good to be true.
The WEIRD Trick
Here's an example query that was having issues. We're selecting some records and ordering by ID.
SELECT *
FROM activities
WHERE account_id IN (999102,989987,809354,100964)
ORDER BY id DESC
LIMIT 10;
Here's an EXPLAIN plan from pganalyze. Look at that! We're spending almost 9 seconds scanning the index for activities.id 😯
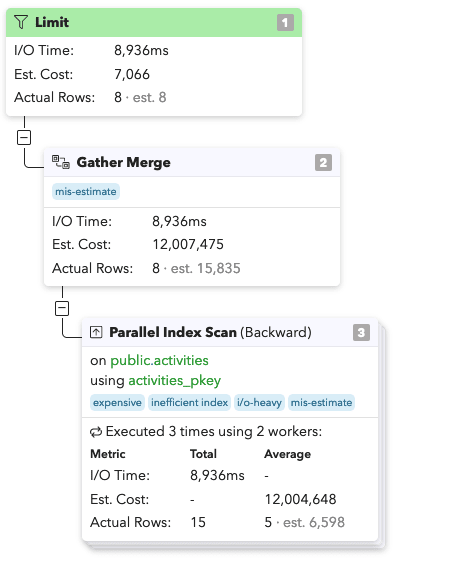
This was baffling to me! We're using an index, why is this slow?!
As any good developer does, I went digging in Stack Overflow for answers. Unfortunately, I can't find the original answer I was looking at, but someone had suggested adding + 0 to the ORDER BY clause.
WHAT?! So I tried it.
EXPLAIN ANALYSE SELECT *
FROM activities
WHERE account_id IN (999102,989987,809354,100964)
ORDER BY id + 0 DESC
LIMIT 10;
Limit (cost=32383.82..32383.84 rows=8 width=149) (actual time=71.250..71.252 rows=8 loops=1)
-> Sort (cost=32383.82..32410.22 rows=10557 width=149 (actual time=71.249..71.250 rows=8 loops=1)
Sort Key: ((id + 0)) DESC
Sort Method: top-N heapsort Memory: 26kB
-> Index Scan using index_activities_on_account_user_id on activities (cost=0.57..32172.68 rows=10557 width=149) (actual time=2.292..71.154 rows=132 loops=1)
Index Cond: (account_user_id = ANY ('{999102,989987,809354,100964}'::integer[]))
Planning Time: 0.122 ms
Execution Time: 71.279 ms
🤯 71.279 ms!!!!!
What in the ACTUAL is happening here?
Well, first, you should know that this table is pretty big. There are just under 100,000,000 records in it. AND, you should know that in some cases, this query can return LOTS of records without the LIMIT in there. In the EXPLAIN plan screen shot above, you can see that the query found just under 9,000 records, but couldn't apply the LIMIT until they were sorted.
Another thing to know here is that this table is busy. We add almost 1,000,000 records in a day. Which means that those 9,000 records have IDs that are pretty far apart. There are big gaps between the numbers returned in the ID column.
Imagine this query returned 100 records, but the IDs were more than 100 apart. E.g., IDS 100, 200, 300...etc. When postgres is trying to sort these records it does a reverse scan through the index and has to read the order of EVERY number including the ones not returned by the query.
So what is this magic + 0 doing? Adding + 0 to the ORDER BY clause forces Postgres to load the records into memory and sort them without the index, which is way faster. You can see in the explain plan above, that the sort in memory was super fast.
Why You Probably Shouldn't Do This in Production
This really depends on your data. I knew that only a small percentage of users were experiencing really slow requests due to this query, but I didn't know what the impact of the + 0 magic would be on users that have fewer activities records. So I ran an experiment using GitHub's Scientist gem.
The results of the experiment are still coming in, but so far, the original ORDER BY is almost tied with ORDER BY id + 0 for average execution time. However, the 95 percentile execution time (meaning 5% of queries are slower than this number), are way out of sync! ORDER BY id + 0 is almost twice as slow in the 95 percentile category.
The results of the experiment tell me that overall, ORDER BY with an index scan might cause timeouts for some users, but ORDER BY id + 0 with no index scan seems to cause slower queries overall for most users.
Looks like I'm going to have to find a different solution to this problem.
Conclusion
Adding + 0 to your ORDER BY id is a wacky trick that will speed up queries when the index is HUGE and the IDs returned have big intervals.
However, it won't always work. Indexes are still fast! Test your queries safely in production to make sure that you're not making a worse experience overall to save a few slow queries.



